makemore: part 1
i built a character-level language model from scratch to prove a point: a pure statistical counting model and a neural network optimized via gradient descent converge to the exact same math. source code.
the baseline (counting)
i mapped bigram frequencies from 32,000 names into a 27x27 tensor. applying laplace smoothing (+1 count) prevented infinite loss from zero-probability bigrams before normalizing.
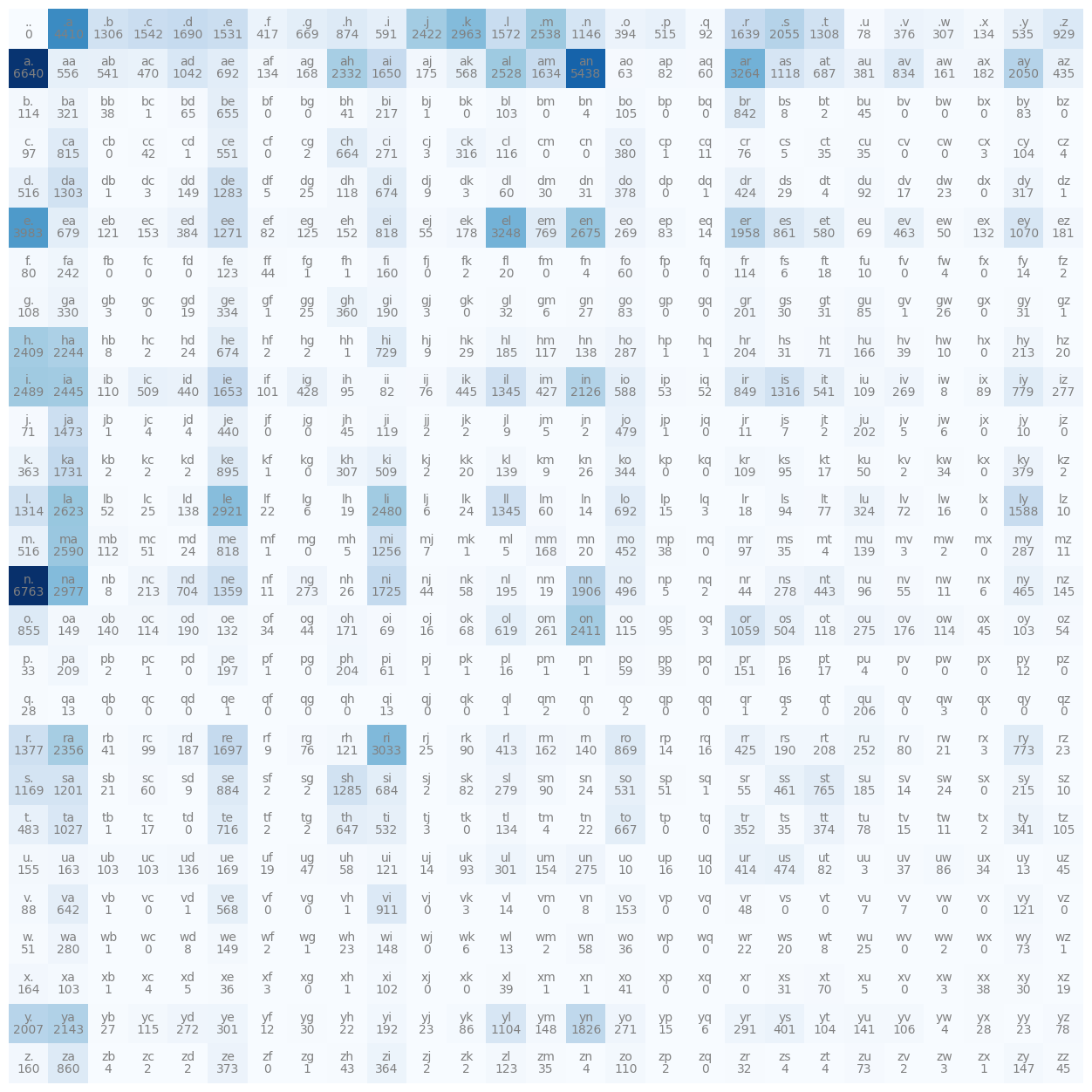
evaluation (nll)
we use negative log-likelihood (nll) to measure performance.
- random guess (1/27 chance): 3.29 loss
- trained statistical matrix: 2.45 loss
the neural network
i threw out the counting matrix and built a single-layer neural net in pytorch (linear layer -> softmax) to learn these probabilities from 228,000+ one-hot encoded bigrams.
- forward pass:
logits = x_enc @ W->exp->normalize - optimization: gradient descent + l2 regularization (which acts mathematically identically to laplace smoothing).
the result
after 500 epochs, the neural network converged to ~2.45 loss—matching the statistical baseline perfectly. the model is just a bigram, so the names are basically phonetically correct gibberish, but the architecture works.
generated names: tonnian kighy alie teresh